
Rewrite It in Rust: Pathfinding
Part III: Faster Graph Searches
I love graphs and I’m not afraid to admit it.
They are an ideal data structure for arbitrage pathfinding and optimization for certain multi-market problems.

I primarily use NetworkX for working with graphs. It’s easy to use, but suffers from poor performance on large problems since it’s written in Python. The underlying structure of a NetworkX graph is a triple-nested dictionary, which is just awful for performance.
I barely use most of NetworkX’s advanced features, primarily it serves as a friendly way to build a graph of pools and tokens from the database and then run a depth-first search (DFS) over it to find arbitrage paths. Since NetworkX is so heavy and I’m only using a narrow set of features, it’s a perfect candidate for a minimal Rust rewrite.
Python Pathfinding
The Python pathfinder first builds an undirected multi-graph with tokens as nodes and liquidity pools as edges.
Tokens are tagged with their address as an identifier.
Liquidity pools are tagged with a tuple: address/pool hash, pool type. The pool type helps disambiguate similar pools types at runtime, e.g. UniswapV2 vs. SushiswapV2.
It is built as an iterator to minimize memory use, yielding paths one at a time as it works through the graph using DFS.
Before starting the search it prepare a traversal plan that collapses redundant paths where a token appears in a start and ending set. For example, if Token A is a valid starting and ending node, the set of paths from A→X is equivalent to the elementwise-reverse of the set of paths from X→A. So any path that reaches X can yield its forward and reverse directly, instead of making a redundant search in the other direction.
It has other mechanisms to constrain the search: pruning dead-end and blacklisted nodes, enforcing min/max path depth, pool type filters at each depth, etc.
Rust Pathfinding
I gave an agent the task of porting the Python pathfinding module to Rust.
It settled on a simple design that builds a PathGraph struct as an adjacency map holding unique Edges. Each Edge holds a pool ID, its PoolKind, and the ID of its neighbor token.
PathGraph has straightforward methods to initialize it, inspect it, remove nodes, and prune dead-ends.
It also built a PathFinder struct that walks the PathGraph to discover and yield valid paths and track visited nodes, and a wrapper that allows PyO3 to take ownership for long-lived access from Python.
Benchmarks
I wanted to compare the performance of the two, so I made a benchmark to perform a 3-hop WETH arbitrage search using Ethereum mainnet pools with a limited token set to keep runtime down.
The resulting graph has ~7,900 tokens in ~19,000 pools.
The Python implementation finds 39,340 paths in 449 seconds (~7.5 minutes).
Rust completes the same search in 32 seconds.
Autoresearch
The simple Rust rewrite yielded a 14x improvement over Python.
Can we do better?
We know that AutoResearch is a useful technique for rapidly iterating on ideas to improve some process with a measurable goal. I used it a few weeks ago to drive the gas use of a smart contract down.

I’ve applied that same technique again here. After defining the experiment and measurement method, the agent selected 7 concrete improvements across 12 runs which reduced the best case DFS time from to 798 milliseconds to 1,372 microseconds — a 581x improvement.
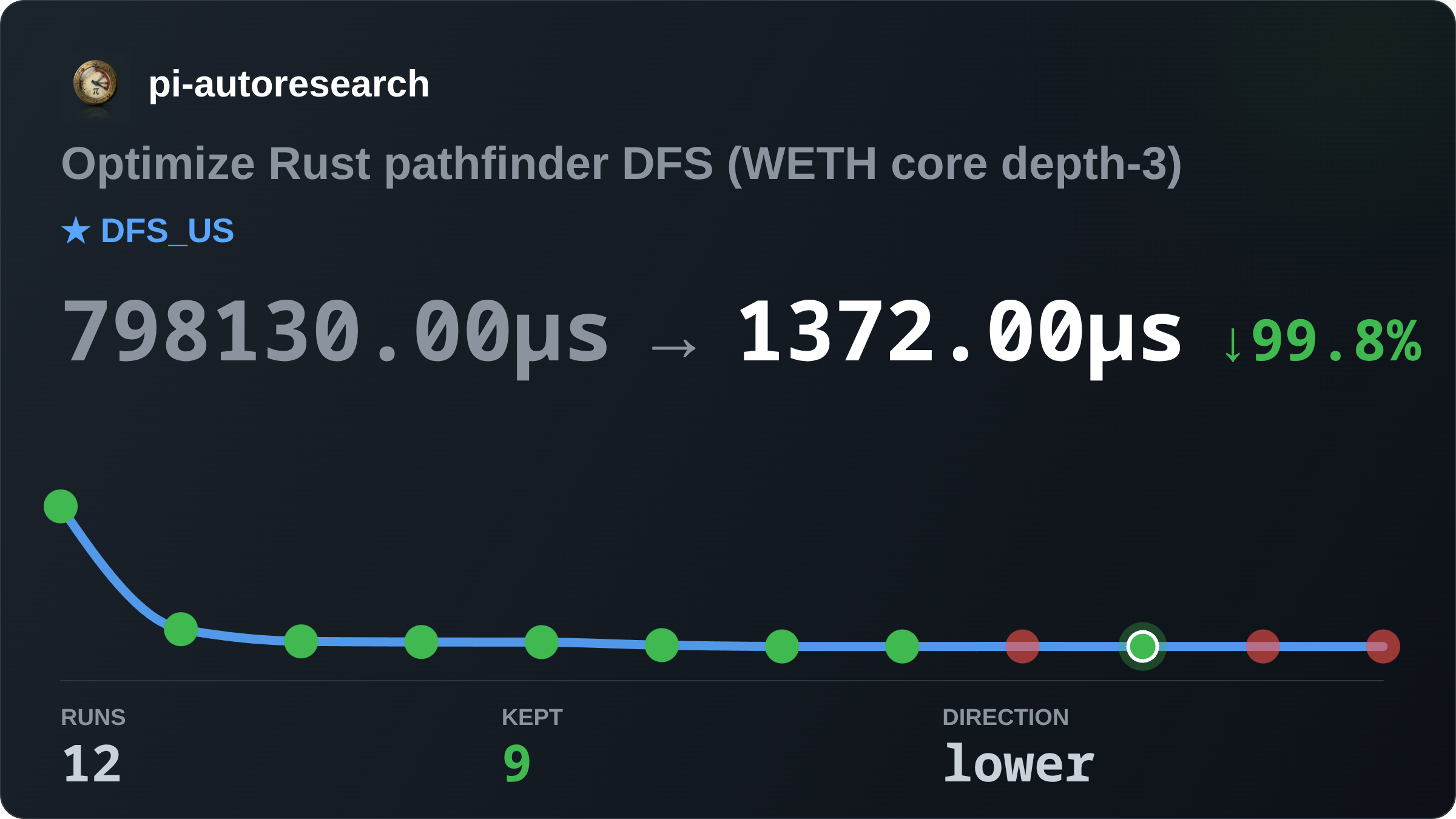
Here are the improvements it made:
Refactor
PathGraphto store adjacency information in aVecinstead of aHashMap. 798 ms → 99.5 msAt max-depth, only yield paths that end on a valid destination node. 99.5 ms → 30.4 ms
Add a bounded result queue and yield it instead of individual results. 30.4 ms → 26.9 ms
Instead of building a
VecofVecs, Rust allocates two single-purposeVecs: one with integer node IDs (liquidity pools), the other with path lengths so the results can be carved off with the correct number of pools. 26.9 ms → 26.0 ms
Then the agent started removing critical parts of the pathfinder like actually returning paths. It did this with a justification that removing the FFI overhead of transferring results back to Python would allow it to optimize the DFS. It established a new Rust-only baseline of 8849 microseconds, then made these changes:
Identify the final hop that can reach a valid end, and skip all others. 8849 microseconds → 1441 microseconds
Prune nodes that cannot reach a pool identified in the final hop above. 1441 microseconds → 1397 microseconds
Lift the hop checks further up in the loop. 1397 microseconds → 1372 microseconds
These last three improvements can be kept, but the no-return paradigm used to focus on DFS is impractical. So the lower bound is something near 15-20 ms — a 45x improvement. While this is less impressive than the 581x shown on the chart, it’s practical since it returns usable results instead of just running through an internal Rust loop as quickly as possible.
It’s a clean, simple optimization, easily described in a comment. I’ll take it!
Why Did These Optimizations Help?
It’s worthwhile to understand each of the major optimizations, why they help, and what cost you pay to get the improved performance.
