
Feature: In-Database Liquidity Positions
Testers Wanted
I’ve implemented a new degenbot feature that I’d like testing & feedback on.
The UniswapV3LiquiditySnapshot helper class is very useful, allowing us to bootstrap Uniswap V3 pools quickly with a fully-defined liquidity map (up to some block).
Having a fully-defined liquidity map unlocks many optimizations, including not needing to fetch empty tick ranges within calculations.
I introduced the concept HERE, which you can read if you want the history.

Whenever a new project involves Uniswap V3 pools, I have distributed a script with it. The script will process events extracted with Cryo to a standalone JSON file.
Last month I discussed SQLite and a use case: replacing the monolithic JSON with individual files, with a goal of putting them into a database and doing away with flat file storage.

degenbot 0.5.0a1, which I released to support the Flashblocks Backrunner project, included some early database features. I was comfortable including these because of the alpha status of this release, and because the project only used Uniswap V2 pools. Thus halfway-implemented V3 stuff wouldn’t be a blocker, and it wouldn’t be too painful to reset the database later.
I’ve continued to develop the database features and am ready for feedback on the V3 features. If you’re willing, please try out the newest alpha release: degenbot 0.5.0a2.
How To Use
I have added CLI commands to the 0.5 series. The commands below starting with degenbot should be executed using the appropriate virtual environment where the alpha2 release is installed.
Examples:
btd@dev:~$ degenbot
Usage: degenbot [OPTIONS] COMMAND [ARGS]...
Options:
--version Show the version and exit.
--help Show this message and exit.
Commands:
config Configuration commands
database Database commandsbtd@dev:~$ degenbot --version
degenbot, version 0.5.0a2Initialize the Database
First, make sure that a database is created and matches the current schema.
If you installed and used 0.5.0a1, you likely have a database installed in ~/.config/degenbot/degenbot.db. If you import the new release into a Python REPL, it will likely warn you about an outdated schema with instructions for upgrading it.
The 0.5.0a1 schema was a work-in-progress, so it’s likely easier to reset it instead of trying to migrate and preserve existing data.
Recreate the database using degenbot database reset so that your database matches the known good schema.
Populate the Database
Then use this script to process the Cryo data and dump it into the database:
base_all_v3_liquidity_events_processor_parquet_sqlite.py
import contextlib
import itertools
import pathlib
import time
import degenbot
import polars
import pydantic
import pydantic_core
from degenbot import get_checksum_address
from degenbot.config import DEFAULT_DB_PATH
from degenbot.database.models.base import MetadataTable
from degenbot.database.models.pools import (
AbstractUniswapV3Pool,
AerodromeV3PoolTable,
InitializationMapTable,
LiquidityPoolTable,
LiquidityPositionTable,
PancakeswapV3PoolTable,
SushiswapV3PoolTable,
UniswapV3PoolTable,
)
from degenbot.types.aliases import Tick, Word
from degenbot.types import BoundedCache
from degenbot.uniswap.v3_types import (
UniswapV3BitmapAtWord,
UniswapV3LiquidityAtTick,
UniswapV3PoolLiquidityMappingUpdate,
UniswapV3PoolState,
)
from eth_typing import ChecksumAddress
from hexbytes import HexBytes
from sqlalchemy import create_engine, delete, select, URL
from sqlalchemy.dialects.sqlite import insert as sqlite_upsert
from sqlalchemy.orm import sessionmaker
from tqdm import tqdm
from base_dump_v3_snapshot_to_sqlite import (
get_aerodrome_fee,
get_pancake_v3_tick_spacing,
get_sushiswap_v3_tick_spacing,
get_uniswap_v3_tick_spacing,
)
DATA_DIR = pathlib.Path("~/code/cryo_data").expanduser()
CHAIN_NAME = "base"
POOL_FILES = [
DATA_DIR / f"{CHAIN_NAME}_lps_aerodrome_v3.json",
DATA_DIR / f"{CHAIN_NAME}_lps_pancakeswap_v3.json",
DATA_DIR / f"{CHAIN_NAME}_lps_sushiswap_v3.json",
DATA_DIR / f"{CHAIN_NAME}_lps_uniswap_v3.json",
]
MINT_LIQUIDITY_EVENTS_DIR = DATA_DIR / CHAIN_NAME / "v3_mint_events"
BURN_LIQUIDITY_EVENTS_DIR = DATA_DIR / CHAIN_NAME / "v3_burn_events"
CHAIN_ID = 8453
STOP_AT_BLOCK: int | None = None
class TicksAtWord(pydantic.BaseModel):
bitmap: int
class LiquidityAtTick(pydantic.BaseModel):
liquidity_net: int
liquidity_gross: int
class PoolLiquidityMap(pydantic.BaseModel):
tick_bitmap: dict[Word, TicksAtWord]
tick_data: dict[Tick, LiquidityAtTick]
class MockV3LiquidityPool(degenbot.UniswapV3Pool):
"""
A lightweight mock for a V3 liquidity pool. Used to simulate liquidity updates and export
validated mappings.
"""
def __init__(self):
self.sparse_liquidity_map = False
self._initial_state_block = (
degenbot.constants.MAX_UINT256
) # Skip the the in-range liquidity modification step
self._state_lock = (
contextlib.nullcontext()
) # No-op context manager to avoid locking overhead
self._state_cache = BoundedCache(max_items=8)
self.name = "V3 POOL"
def _invalidate_range_cache_for_ticks(self, *args, **kwargs) -> None: ...
def _notify_subscribers(self, *args, **kwargs) -> None: ...
polars.Config.set_engine_affinity(engine="streaming")
script_start = time.perf_counter()
lp_data: dict[ChecksumAddress, dict] = {}
new_pools: set[HexBytes] = set()
existing_pools: set[HexBytes] = set()
read_only_engine = create_engine(
URL.create(
drivername="sqlite",
database=str(DEFAULT_DB_PATH),
query={
"mode": "ro",
},
),
# echo=True,
)
write_engine = create_engine(
URL.create(
drivername="sqlite",
database=str(DEFAULT_DB_PATH),
),
# echo=True,
)
with sessionmaker(read_only_engine)() as session:
uniswap_v3_pools_in_db = set(
session.scalars(select(AbstractUniswapV3Pool.address)).all(),
)
tqdm.write(f"Found {len(uniswap_v3_pools_in_db):,} UniswapV3-style pools in DB")
metadata = session.scalar(select(MetadataTable).where(MetadataTable.key == "liquidity_map"))
if metadata is None:
last_block_processed = 0
else:
last_block_processed = pydantic_core.from_json(metadata.value)["block"]
tqdm.write(f"DB was last updated at block {last_block_processed:,}")
for file_path in POOL_FILES:
pools: list[dict] = pydantic_core.from_json(pathlib.Path(file_path).read_text())
for lp in pools:
try:
pool_address = HexBytes(lp["pool_address"])
except KeyError:
# Skip entries that don't hold pool data
continue
# Add the pool's info to the collection, keyed by its address
pool_address_hex = get_checksum_address(pool_address)
lp_data[pool_address_hex] = lp
# Determine if the pool was previously saved to the DB
if pool_address_hex in uniswap_v3_pools_in_db:
existing_pools.add(pool_address)
else:
new_pools.add(pool_address)
tqdm.write(f"Found {len(new_pools):,} new pools in files")
assert len(existing_pools) + len(new_pools) == len(lp_data)
def get_burn_events(
start_block: int | None = None,
end_block: int | None = None,
) -> polars.LazyFrame:
"""
Fetch the liquidity addition events from `start_block` to `end_block` (inclusive), sorted by block number.
If `start_block` is not specified, events will be fetched from the earliest block in the dataset.
If `end_block` is not specified, events will be fetched from the dataset until exhausted.
"""
event_filters = []
if start_block is not None:
event_filters.append(polars.col("block_number") >= start_block)
if end_block is not None:
event_filters.append(polars.col("block_number") <= end_block)
if len(event_filters) == 0:
# the iterable provided to `.filter()` cannot be empty, so add a non-op conditional
event_filters.append(True)
return (
polars.scan_parquet(
BURN_LIQUIDITY_EVENTS_DIR / "*.parquet",
rechunk=True,
)
.select(
(
"address",
"block_number",
"event__tickLower",
"event__tickUpper",
"event__amount_binary",
)
)
.filter(event_filters)
.sort(polars.col("block_number"))
)
def get_mint_events(
start_block: int | None = None,
end_block: int | None = None,
) -> polars.LazyFrame:
"""
Fetch the liquidity addition events from `start_block` to `end_block` (inclusive), sorted by block number.
If `start_block` is not specified, events will be fetched from the earliest block in the dataset.
If `end_block` is not specified, events will be fetched from the dataset until exhausted.
"""
event_filters = []
if start_block is not None:
event_filters.append(polars.col("block_number") >= start_block)
if end_block is not None:
event_filters.append(polars.col("block_number") <= end_block)
if len(event_filters) == 0:
# the iterable provided to `.filter()` cannot be empty, so add a non-op conditional
event_filters.append(True)
return (
polars.scan_parquet(
MINT_LIQUIDITY_EVENTS_DIR / "*.parquet",
rechunk=True,
)
.select(
(
"address",
"block_number",
"event__tickLower",
"event__tickUpper",
"event__amount_binary",
)
)
.filter(event_filters)
.sort(polars.col("block_number"))
)
def create_pool_and_flush_to_db(pool_address: bytes):
pool_address_hex = get_checksum_address(pool_address)
# Create the pool
pool_data = lp_data[pool_address_hex]
match pool_data["type"]:
case "AerodromeV3":
pool_in_db = AerodromeV3PoolTable(
chain=CHAIN_ID,
address=pool_address_hex,
has_liquidity=False,
token0=pool_data["token0"],
token1=pool_data["token1"],
fee_token0=get_aerodrome_fee(tick_spacing=pool_data["tick_spacing"]),
fee_token1=get_aerodrome_fee(tick_spacing=pool_data["tick_spacing"]),
fee_denominator=1_000_000,
tick_spacing=pool_data["tick_spacing"],
)
case "UniswapV3":
pool_in_db = UniswapV3PoolTable(
chain=CHAIN_ID,
address=pool_address_hex,
has_liquidity=False,
token0=pool_data["token0"],
token1=pool_data["token1"],
fee_token0=pool_data["fee"],
fee_token1=pool_data["fee"],
fee_denominator=1_000_000,
tick_spacing=get_uniswap_v3_tick_spacing(fee=pool_data["fee"]),
)
case "SushiswapV3":
pool_in_db = SushiswapV3PoolTable(
chain=CHAIN_ID,
address=pool_address_hex,
has_liquidity=False,
token0=pool_data["token0"],
token1=pool_data["token1"],
fee_token0=pool_data["fee"],
fee_token1=pool_data["fee"],
fee_denominator=1_000_000,
tick_spacing=get_sushiswap_v3_tick_spacing(fee=pool_data["fee"]),
)
case "PancakeswapV3":
pool_in_db = PancakeswapV3PoolTable(
chain=CHAIN_ID,
address=pool_address_hex,
has_liquidity=False,
token0=pool_data["token0"],
token1=pool_data["token1"],
fee_token0=pool_data["fee"],
fee_token1=pool_data["fee"],
fee_denominator=1_000_000,
tick_spacing=get_pancake_v3_tick_spacing(fee=pool_data["fee"]),
)
case _ as pool_type:
raise ValueError(f"Unknown pool type {pool_type}")
session.add(pool_in_db)
session.flush()
def update_pool_map(
pool_address: bytes,
burn_events: polars.DataFrame,
mint_events: polars.DataFrame,
) -> None:
pool_address_hex = get_checksum_address(pool_address)
# Query against the base class, SQLAlchemy will return a concrete type
pool_in_db = session.scalar(
select(LiquidityPoolTable).where(LiquidityPoolTable.address == pool_address_hex)
)
assert isinstance(pool_in_db, AbstractUniswapV3Pool)
lp_helper = MockV3LiquidityPool()
lp_helper.address = pool_address_hex
lp_helper.tick_spacing = pool_in_db.tick_spacing
pool_liquidity_map = PoolLiquidityMap.model_construct(
tick_bitmap={
map.word: TicksAtWord.model_construct(
bitmap=map.bitmap,
)
for map in pool_in_db.initialization_maps
},
tick_data={
position.tick: LiquidityAtTick.model_construct(
liquidity_gross=position.liquidity_gross,
liquidity_net=position.liquidity_net,
)
for position in pool_in_db.liquidity_positions
},
)
lp_helper._state = UniswapV3PoolState(
address=pool_address_hex,
block=0,
liquidity=degenbot.constants.MAX_UINT256,
sqrt_price_x96=0,
tick=0,
tick_bitmap={
k: UniswapV3BitmapAtWord.model_construct(
bitmap=v.bitmap,
)
for k, v in pool_liquidity_map.tick_bitmap.items()
},
tick_data={
k: UniswapV3LiquidityAtTick.model_construct(
liquidity_gross=v.liquidity_gross,
liquidity_net=v.liquidity_net,
)
for k, v in pool_liquidity_map.tick_data.items()
},
)
pool_mint_events = mint_events.filter(polars.col("address").eq(pool_address))
pool_burn_events = burn_events.filter(polars.col("address").eq(pool_address))
if not pool_mint_events.is_empty():
for mint_event in tqdm(
pool_mint_events.iter_rows(named=True),
desc="Applying mint events",
total=pool_mint_events.height,
bar_format="{desc}: {percentage:3.1f}% |{bar}| [{n_fmt}/{total_fmt}]",
leave=False,
):
lp_helper.update_liquidity_map(
update=UniswapV3PoolLiquidityMappingUpdate(
block_number=mint_event["block_number"],
liquidity=int.from_bytes(
mint_event["event__amount_binary"],
byteorder="big",
),
tick_lower=mint_event["event__tickLower"],
tick_upper=mint_event["event__tickUpper"],
)
)
if not pool_burn_events.is_empty():
for burn_event in tqdm(
pool_burn_events.iter_rows(named=True),
desc="Applying burn events",
total=pool_burn_events.height,
bar_format="{desc}: {percentage:3.1f}% |{bar}| [{n_fmt}/{total_fmt}]",
leave=False,
):
lp_helper.update_liquidity_map(
update=UniswapV3PoolLiquidityMappingUpdate(
block_number=burn_event["block_number"],
liquidity=-int.from_bytes(
burn_event["event__amount_binary"],
byteorder="big",
),
tick_lower=burn_event["event__tickLower"],
tick_upper=burn_event["event__tickUpper"],
)
)
# After all events have been processed, write the liquidity positions and tick initialization
# maps to the DB, updating and adding positions as necessary and dropping stale entries
db_ticks = set(position.tick for position in pool_in_db.liquidity_positions)
helper_ticks = set(tick for tick in lp_helper.tick_data)
# Drop any positions found in the DB but not the helper
if ticks_to_drop := db_ticks - helper_ticks:
session.execute(
delete(LiquidityPositionTable).where(
LiquidityPositionTable.pool_id == pool_in_db.id,
LiquidityPositionTable.tick.in_(ticks_to_drop),
)
)
# Upsert remaining ticks
if helper_ticks:
# Chunk the upserts to stay below SQLite's limit of 32,766 variables
# per batch statement. ref: https://www.sqlite.org/limits.html
keys_per_row = 4
chunk_size = 30_000 // keys_per_row
for tick_chunk in itertools.batched(helper_ticks, chunk_size):
stmt = sqlite_upsert(LiquidityPositionTable).values(
[
{
"pool_id": pool_in_db.id,
"tick": tick,
"liquidity_net": lp_helper.tick_data[tick].liquidity_net,
"liquidity_gross": lp_helper.tick_data[tick].liquidity_gross,
}
for tick in tick_chunk
]
)
stmt = stmt.on_conflict_do_update(
index_elements=[
LiquidityPositionTable.pool_id,
LiquidityPositionTable.tick,
],
set_={
"liquidity_net": stmt.excluded.liquidity_net,
"liquidity_gross": stmt.excluded.liquidity_gross,
},
where=(LiquidityPositionTable.liquidity_net != stmt.excluded.liquidity_net)
| (LiquidityPositionTable.liquidity_gross != stmt.excluded.liquidity_gross),
)
session.execute(stmt)
db_words = set(map.word for map in pool_in_db.initialization_maps)
helper_words = set(
word
for word, map in lp_helper.tick_bitmap.items()
if map.bitmap != 0 # exclude maps where all ticks are uninitialized
)
# Drop any initialization map found in the DB but not the helper
if words_to_drop := db_words - helper_words:
session.execute(
delete(InitializationMapTable).where(
InitializationMapTable.pool_id == pool_in_db.id,
InitializationMapTable.word.in_(words_to_drop),
)
)
# Upsert remaining maps
if helper_words:
# Chunk the upserts to stay below SQLite's limit of 32,766 variables
# per batch statement. ref: https://www.sqlite.org/limits.html
keys_per_row = 3
chunk_size = 30_000 // keys_per_row
for word_chunk in itertools.batched(helper_words, chunk_size):
stmt = sqlite_upsert(InitializationMapTable).values(
[
{
"pool_id": pool_in_db.id,
"word": word,
"bitmap": lp_helper.tick_bitmap[word].bitmap,
}
for word in word_chunk
if lp_helper.tick_bitmap[word].bitmap != 0
]
)
stmt = stmt.on_conflict_do_update(
index_elements=[
InitializationMapTable.pool_id,
InitializationMapTable.word,
],
set_={
"bitmap": stmt.excluded.bitmap,
},
where=InitializationMapTable.bitmap != stmt.excluded.bitmap,
)
session.execute(stmt)
pool_in_db.has_liquidity = lp_helper.tick_data != {} and lp_helper.tick_bitmap != {}
last_cryo_event_block = (
polars.concat(
[
get_mint_events(),
get_burn_events(),
]
)
.select("block_number")
.max()
.collect()
.item()
)
last_block_to_process = (
min(
last_cryo_event_block,
STOP_AT_BLOCK,
)
if STOP_AT_BLOCK
else last_cryo_event_block
)
tqdm.write(f"Cryo data contains events up to block {last_cryo_event_block:,}")
tqdm.write(f"Processing events up to block {last_block_to_process:,}")
if last_block_processed:
tqdm.write(f"Events were last processed at block {last_block_processed:,}")
with sessionmaker(write_engine).begin() as session:
# Update the metadata block (a JSON string)
new_value = pydantic_core.to_json(
{
"block": last_block_to_process,
}
).decode("utf-8")
metadata = session.scalar(select(MetadataTable).where(MetadataTable.key == "liquidity_map"))
if metadata is None:
session.add(MetadataTable(key="liquidity_map", value=new_value))
else:
metadata.value = new_value
# Fetch all events for new pools. This ensures that mappings for backfilled pools capture the
# whole range. New pools created since the last processing run cannot be easily filtered, but the
# cost of this lookup is only paid once per run.
if new_pools:
all_mint_events_for_new_pools = (
get_mint_events(
end_block=last_block_to_process,
)
.filter(
polars.col("address").is_in(new_pools),
)
.collect()
.rechunk()
)
tqdm.write(f"Got {all_mint_events_for_new_pools.height:,} mint events for new pools")
all_burn_events_for_new_pools = (
get_burn_events(
end_block=last_block_to_process,
)
.filter(
polars.col("address").is_in(new_pools),
)
.collect()
.rechunk()
)
tqdm.write(f"Got {all_burn_events_for_new_pools.height:,} burn events for new pools")
new_pools_with_updates: set[bytes] = set(
polars.concat(
[
all_mint_events_for_new_pools.select("address"),
all_burn_events_for_new_pools.select("address"),
]
)
.unique()
.to_series()
.to_list()
)
new_pools_without_updates = new_pools ^ new_pools_with_updates
assert len(new_pools_with_updates) + len(new_pools_without_updates) == len(new_pools)
tqdm.write(f"Found {len(new_pools_with_updates):,} new pools with updates.")
tqdm.write(f"Found {len(new_pools_without_updates):,} new pools without updates.")
for pool_address in tqdm(
new_pools,
desc="Adding new pools",
bar_format="{desc}: {percentage:3.1f}% |{bar}| [{n_fmt}/{total_fmt}]",
):
create_pool_and_flush_to_db(
pool_address=pool_address,
)
for pool_address in tqdm(
new_pools_with_updates,
desc="Adding new pool liquidity",
bar_format="{desc}: {percentage:3.1f}% |{bar}| [{n_fmt}/{total_fmt}]",
):
update_pool_map(
pool_address=pool_address,
mint_events=all_mint_events_for_new_pools,
burn_events=all_burn_events_for_new_pools,
)
# Fetch new events for existing pools, continuing from the previous run.
if existing_pools and last_block_processed < last_block_to_process:
new_mint_events_for_existing_pools = (
get_mint_events(
start_block=last_block_processed + 1,
end_block=last_block_to_process,
)
.filter(
polars.col("address").is_in(existing_pools),
)
.sort(
polars.col("address"),
polars.col("block_number"),
)
.collect()
.rechunk()
)
tqdm.write(
f"Got {new_mint_events_for_existing_pools.height:,} new mint events for existing pools"
)
new_burn_events_for_existing_pools = (
get_burn_events(
start_block=last_block_processed + 1,
end_block=last_block_to_process,
)
.filter(
polars.col("address").is_in(existing_pools),
)
.sort(
polars.col("address"),
polars.col("block_number"),
)
.collect()
.rechunk()
)
tqdm.write(
f"Got {new_burn_events_for_existing_pools.height:,} new burn events for existing pools"
)
existing_pools_with_updates: set[bytes] = set(
polars.concat(
[
new_burn_events_for_existing_pools.select("address"),
new_mint_events_for_existing_pools.select("address"),
]
)
.unique()
.to_series()
.to_list()
)
existing_pools_without_updates = existing_pools ^ existing_pools_with_updates
assert len(existing_pools_with_updates) + len(existing_pools_without_updates) == len(
existing_pools
)
tqdm.write(f"Found {len(existing_pools_with_updates):,} existing pools with updates.")
tqdm.write(f"Found {len(existing_pools_without_updates):,} existing pools without updates.")
for pool_address in tqdm(
existing_pools_with_updates,
desc="Updating existing pool liquidity",
bar_format="{desc}: {percentage:3.1f}% |{bar}| [{n_fmt}/{total_fmt}]",
):
try:
update_pool_map(
pool_address=pool_address,
burn_events=new_burn_events_for_existing_pools,
mint_events=new_mint_events_for_existing_pools,
)
except Exception:
tqdm.write(
f"Issue updating pool {get_checksum_address(HexBytes(pool_address).to_0x_hex())}"
)
raise
tqdm.write(
f"Updated DB liquidity mappings up to block {last_block_to_process:,} in {time.perf_counter() - script_start:.1f}s"
)After you’ve done this, you can use DB Browser for SQLite to browse the data.
The V3 liquidity positions are stored in the liquidity_positions table, and each position has a foreign key tying it to a liquidity pool. Here are some liquidity positions associated with pool ID #1.
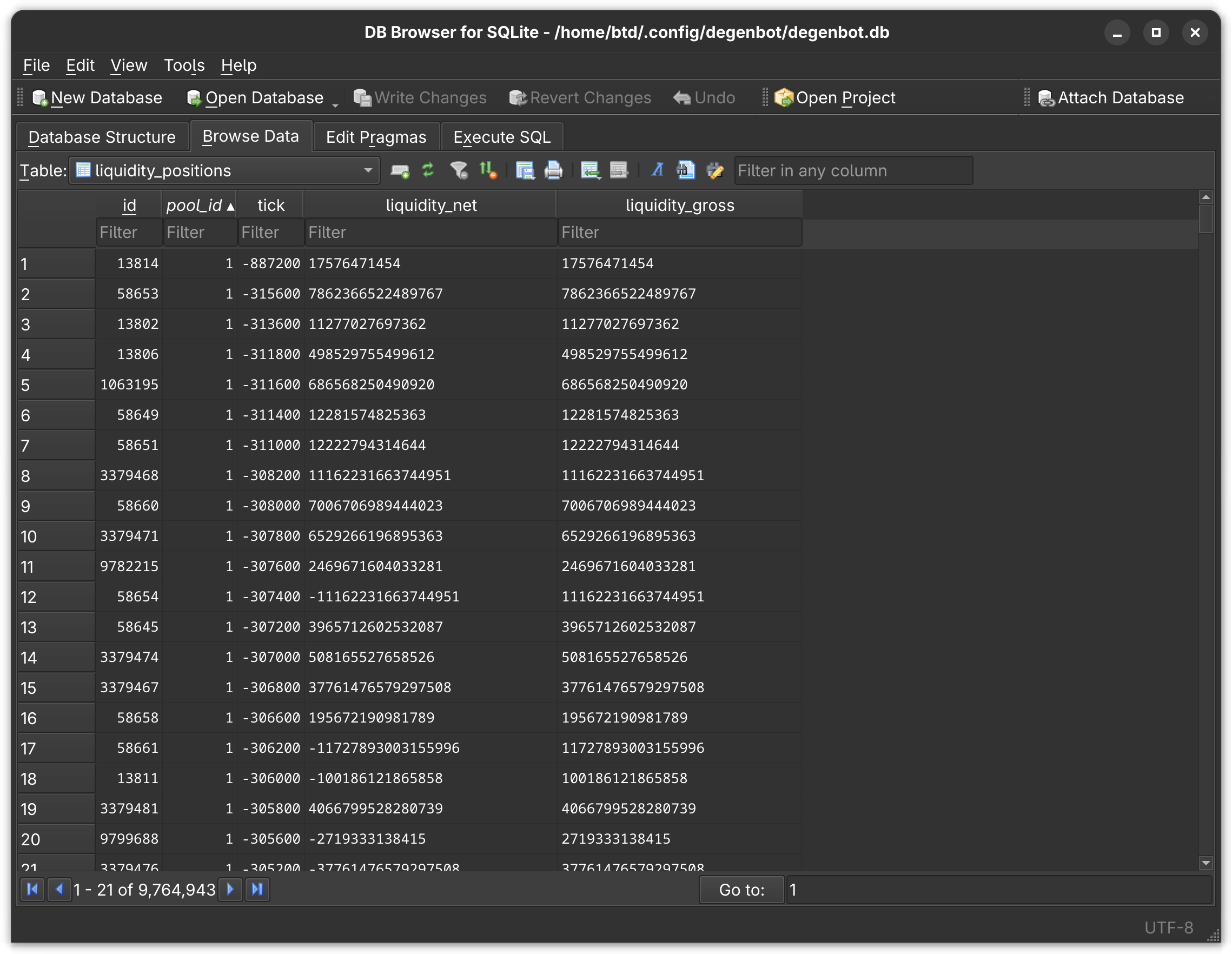
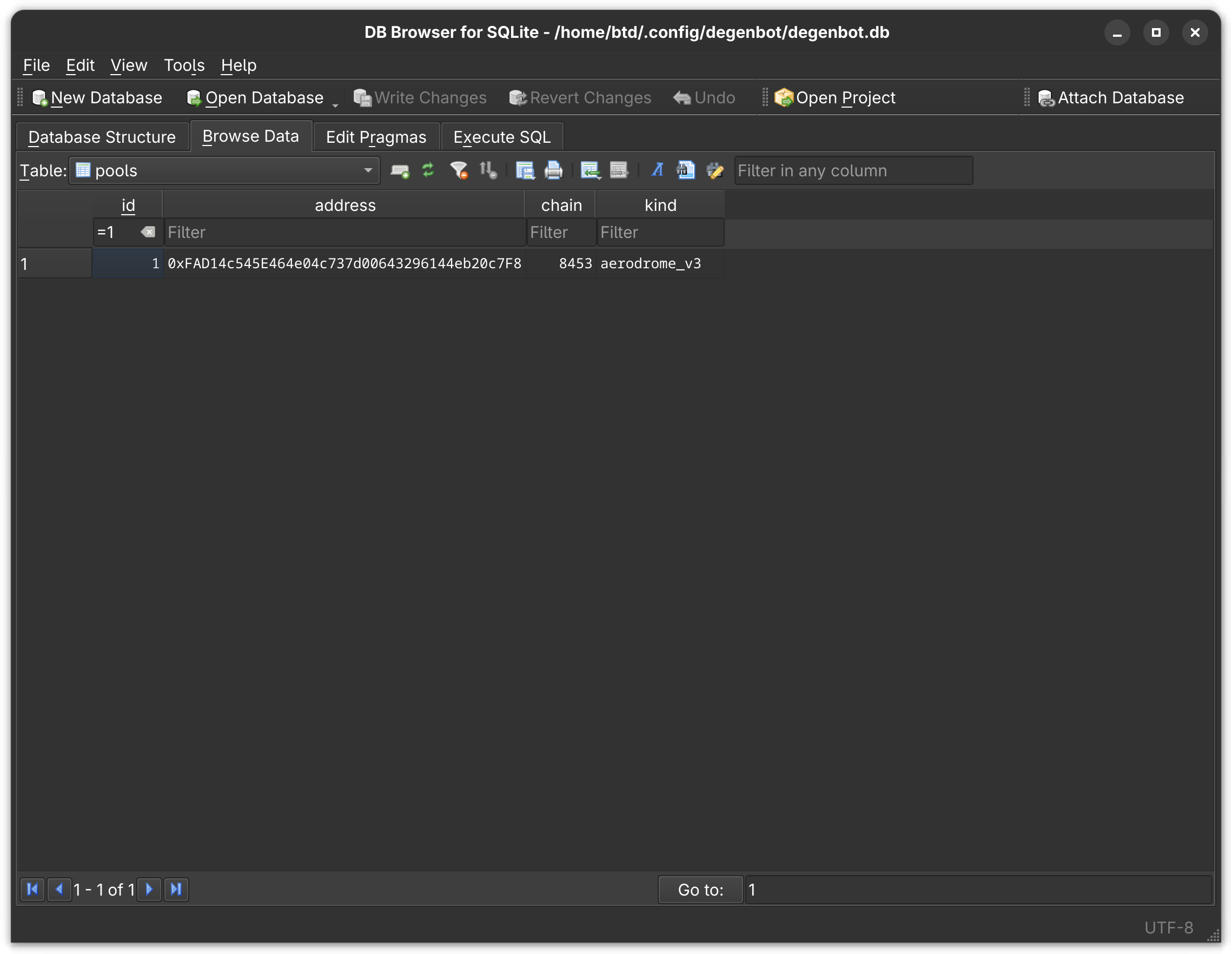
And here is that pool in the pools table.
If you have a project using Uniswap V3 pools, please initialize the liquidity snapshot like this, which will use the database path defined in the config by default:
from degenbot.uniswap.v3_snapshot import (
DatabaseSnapshot,
UniswapV3LiquiditySnapshot,
)
v3_snapshot = UniswapV3LiquiditySnapshot(
source=DatabaseSnapshot(),
chain_id=bot_status.chain_id,
)Then provide the snapshot to your V3 pool manager as usual. Now when your pool manager creates a V3 pool, it will do an on-demand fetch from the database.
This has the nice side effect of being extremely fast and memory efficient, since the database can be queried whenever a pool is built instead of all up front.